再昨日我們把模型詳細的解釋它每行代碼的用途,在最後部分有提到損失值與準確率,今天會講到
那下面就讓我們開始吧!
損失值(Loss Value)和準確值(Accuracy)是用於評估機器學習模型性能的兩個重要指標,損失值用於衡量模型預測的品質,越小越好;而準確值是一個百分比指標,用於衡量模型正確預測的比例,越高越好。這兩個指標通常一起使用,以全面評估模型的性能。
準確率(Accuracy)表示模型正確預測的樣本數占總樣本數的比例使用準確率有幾點好處
1.簡單明瞭:準確率是一個直觀且易於理解的指標,它告訴我們模型在總體上有多少正確的預測。
2.適用範圍廣:準確率適用於多種機器學習問題,包括分類和回歸。對於分類問題,它衡量了模型對類別的正確識別程度;對於回歸問題,可以根據預測值和實際值之間的誤差來計算。
但是它也有不少缺點
1.不適用於不平衡數據集:當不同類別的樣本數目不平衡時,準確率可能會產生偏見,因為模型傾向於預測多數類別,而不是少數類別。在這種情況下,更高的準確率可能不代表模型的真實性能。
比如分辨貓跟狗且數據集9:1,那當把狗分成貓時也只錯一次,準確率卻會很高這時準確率就不準了。
2.無法區分錯誤的嚴重性:準確率對所有錯誤一視同仁,無法區分不同類別的錯誤以及錯誤的嚴重性。有時,某些類別的錯誤可能比其他類別更嚴重,但準確率無法反映這種差異。
3.不考慮預測的不確定性:準確率只告訴我們模型的整體表現,而不提供有關每個預測的置信度信息。在某些應用中,我們需要知道模型對每個預測的置信度,以便更好地做出決策。
因此通常不會只使用準確率來判斷模型好壞。
損失值(Loss Value)用於衡量模型預測和實際值之間的差異,而下面列出使用準確率好處
1.全面反映預測質量:損失值反映了模型對數據的擬合質量,而不僅僅是預測是否正確。它量化了預測值和實際值之間的差距,因此提供了更全面的性能評估。
2.可用於不同任務:損失值可用於各種機器學習任務,包括分類、回歸、生成等。不同任務使用不同的損失函數,但它們都具有類似的目的,即衡量模型的性能。
3.有助於優化模型:深度學習訓練過程的目標是將損失值最小化,這有助於模型學習如何提高預測的準確性。通過梯度下降等優化算法調整模型參數,模型可以不斷優化以降低損失。
但損失值還是有它的缺點在,也因此大部分模型中常需要兩種一起使用,以達到最好效果。
而講到損失就會提到擬合,接下來就介紹擬合與模型好壞的相關知識。
雖然準確率可以在一定程度上判別模型好壞,但上面有提到單看準確率還是難以完全評估模型好壞,這時Loss值所繪製的折線圖就能派上用場,下面我們來看過擬合與欠擬合良好擬合與Loss圖關係
過擬合(Overfitting) 過度擬合是指模型在訓練過程中學習到了訓練數據的細節和噪聲,而無法泛化到新的、未見過的數據。使用訓練數據可以精準辨別,當拿外部數據測試時便無法辨別,無法使用。
當過擬合時Loss圖常會如下圖
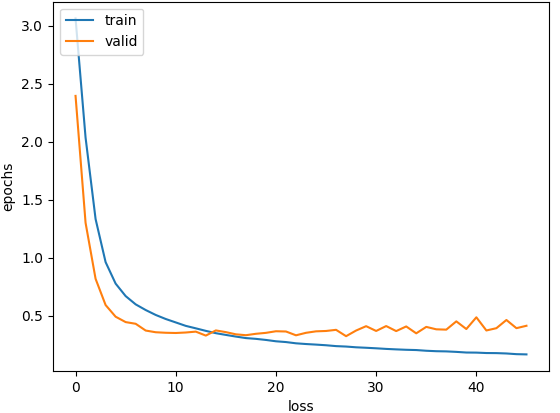
會看到兩條Loss折線圖逐漸發散(這張不太明顯),且驗證的Loss在慢慢增加。
而下面列出一些解決方法:
欠擬合(Underfitting) 是指模型過於簡單或不足以擬合訓練數據中的真實模式,導致模型在訓練數據上的表現不佳。換句話說,模型未能捕捉到數據的複雜性和變異性。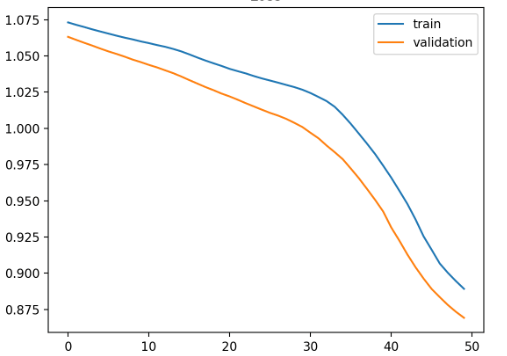
圖片來源:https://blog.csdn.net/u010960155/article/details/104078717
一樣我們列出一些解決方法
良好擬合(good fitting)表示模型在訓練數據上能夠找到適當的模式,並能夠在新數據上進行泛化,即對未見數據也能夠做出準確的預測,是機器學習和深度學習中追求的目標。
如下圖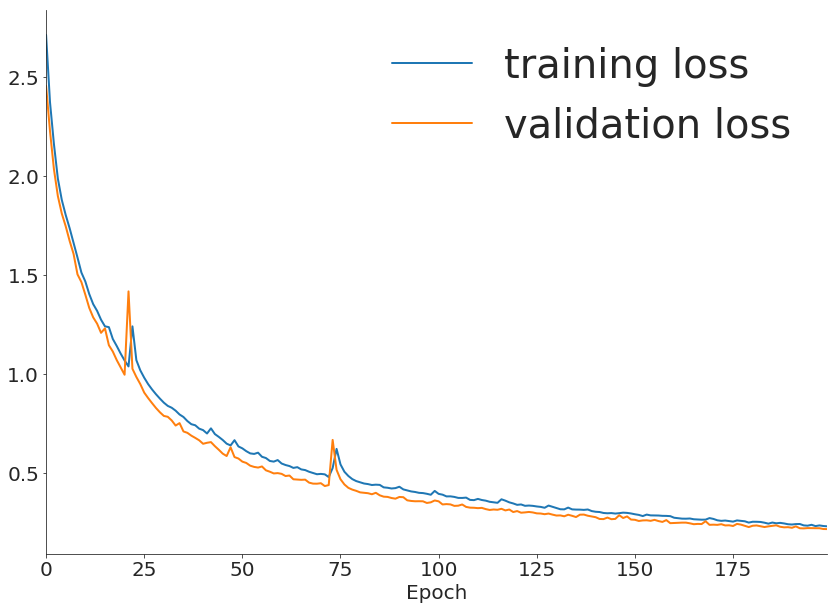
圖片來源:https://www.kaggle.com/discussions/questions-and-answers/156772
以上就是準確值與損失值等等的大概介紹,下面讓我們把昨天的模型加上Loss圖來看看結果吧!
安裝了matplotlib庫,如果沒有安裝可以如前面教學使用CMD以下命令進行安裝:
pip install matplotlib
# 引入必要的庫
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt # Matplotlib函式庫用於繪製折線圖
# 載入MNIST數據集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 數據預處理
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 建立神經網絡模型
model = models.Sequential()
model.add(layers.Flatten(input_shape=(28, 28, 1))) # 將圖像展平成一維數組
model.add(layers.Dense(512, activation='relu')) # 添加一個具有512個神經元的全連接層
model.add(layers.Dense(10, activation='softmax')) # 添加一個具有10個神經元的全連接層(用於10個類別的分類)
# 編譯模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 訓練模型
history = model.fit(train_images, train_labels, epochs=10, batch_size=64, validation_data=(test_images, test_labels)) # 使用 validation_data 同時驗證損失
# 建立 LOSS 圖表
#train loss
plt.plot(history.history['loss'])
#test loss
plt.plot(history.history['val_loss'])
#標題
plt.title('Model loss')
#y軸標籤
plt.ylabel('Loss')
#x軸標籤
plt.xlabel('Epoch')
#顯示折線的名稱
plt.legend(['Train', 'Test'], loc='upper left')
#顯示折線圖
plt.show()
# 評估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
我們使用Matplotlib函式庫繪製折線圖,這裡不多做介紹,
這裡我們故意把模型訓練次數更改成10看看Loss圖會長怎麼樣!
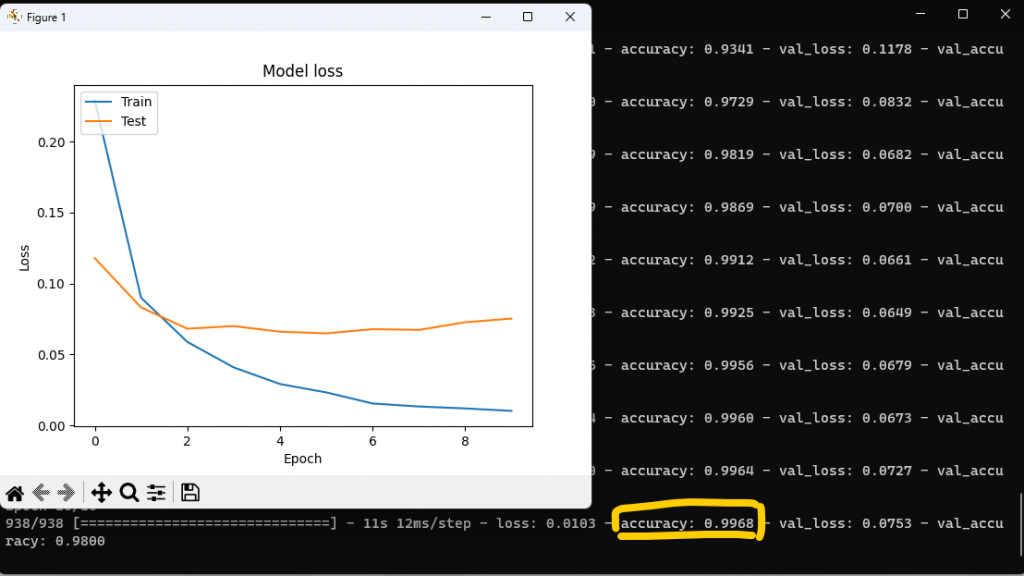
是不是發現圖跟上面說過的過擬合(Overfitting)長的不能說是很像,簡直是一模一樣還更誇張,雖然準確率越來越高,但這時若是將外部訓練集丟入辨別可能就會發現模型變得很差,會看到最佳大概在1-2次訓練間,後面Loss發散也說明了不是訓練次數越高越好!
以上就是今天內容,其實單看程式可能不會到太多,大部分還都是要清楚背後理論知識,不然只是單純程式跑一跑也很難理解到什麼,希望目前的解釋能幫上忙!各位明天見!

